
Most content teams cap out at 20 posts a month. The bottleneck is not writing speed. It is the workflow around the writing.
We rebuilt ours from scratch. Now a small team ships 500+ posts a month across client brands. The drafts are good. The links work. The schema validates. The brand voice holds.
This is the playbook. No theory. No magic. Just the stack, the checks, and the rules we run.
AI content marketing at scale is a systems problem. Treat it like one and the volume math gets easy. Treat it like a writing problem and you ship slop.
Here is what changed for us, and what should change for you.
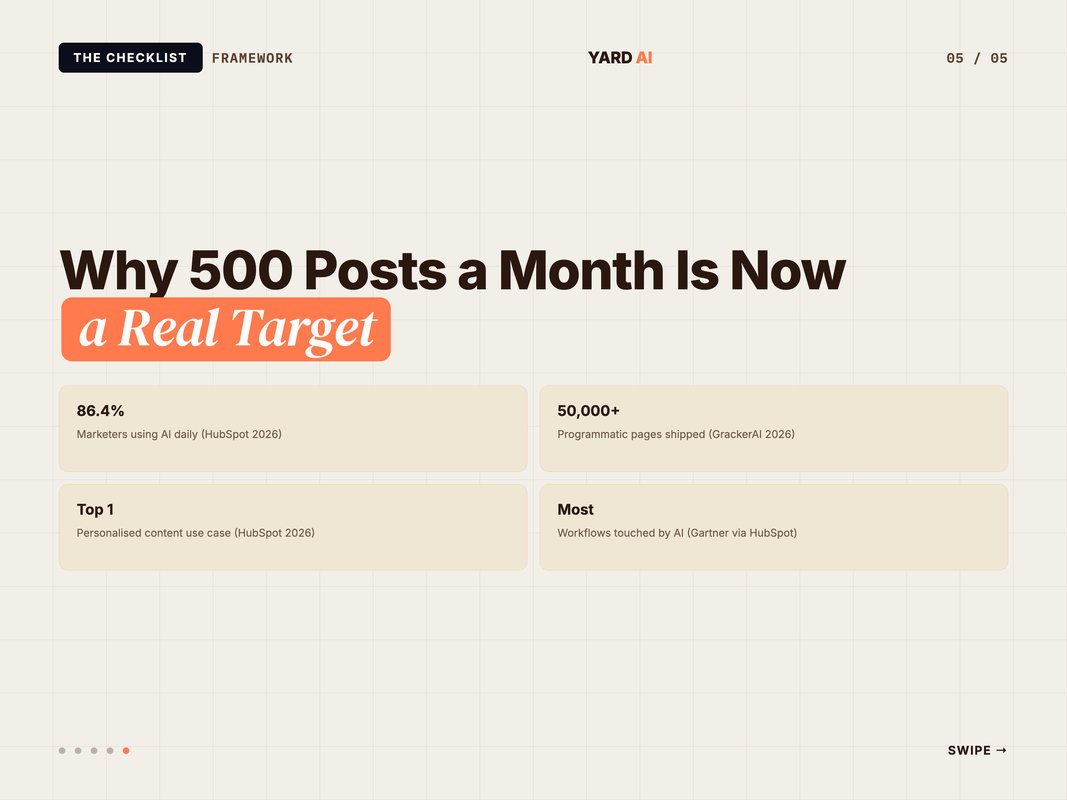
Why 500 Posts a Month Is Now a Real Target
Five years ago, 500 posts a month meant a content farm. Today it means a small team and a clean stack.
The math changed because three things changed. Drafting is near-free. Image generation is near-free. Validation is now scriptable.
That stack collapses the cost per post. It does not collapse the strategy work. Strategy still takes hours.
Most teams chase volume the wrong way. They scale drafts without scaling checks. The output looks fine. The rankings never come.
We learned that the hard way. The first batch of 40 AI-assisted posts ranked for nothing. Every one of them was generic. None had a point of view. None had a citation. The drafts passed the eye test and failed the search test.
So we flipped the model. We treat the writer as a curator. The model writes. The system checks. The human stamps voice and claims at the end.
Quick Facts: AI Content at Scale in 2026
- 86.4% of marketers now use AI tools for content and media work — (Source: HubSpot State of Marketing, 2026 — hubspot.com/state-of-marketing).
- Personalised content is the top AI use case marketers report this year — (Source: HubSpot, 2026 — blog.hubspot.com/marketing).
- Gartner expects AI to touch most marketing workflows by 2026 — (Source: Gartner via HubSpot, 2026 — hubspot.com/state-of-marketing).
- Zapier ships 50,000+ programmatic SEO pages today — (Source: GrackerAI case study, 2026 — gracker.ai/blog).

Q: Is 500 posts a month possible without a huge team?
A: Yes. With a topic engine, a draft engine, an image engine, and a publish engine, two operators can run it. The team grows only at the brief and review layers.
The Four Engines: A Stack Map
Scaling content is not one tool. It is four engines wired together. Each one runs alone. Each one feeds the next.

The order matters. Skip an engine and the next one fails.
The topic engine sets pillar, keyword, and brief. The content engine writes the draft. The image engine fills visuals. The publish engine moves files to the CMS.
You can run each engine on different rails. Most teams use Airtable for topics, Claude or GPT for drafts, fal.io or GPT Image for visuals. Webflow or WordPress for publishing.
The glue is the thing most teams miss. Make, n8n, or a Python script ties them together. Without glue, every step is a copy-paste. With glue, the flow runs in the background.
Tim Soulo at Ahrefs said scaling AI content is the biggest lie in marketing. He is half right. Scaling drafts is easy. Scaling rankings is not.
The fix is in the engine wiring. Each engine has a clear input and a clear output. The contract between them is strict. No fuzzy hand-offs.
Q: Which engine should a team build first?
A: Build the publish engine first. Most teams have drafts piling up and no rails to ship them. Once shipping is automated, the upstream engines have a reason to run.
Engine One: The Topic Engine
The topic engine is your funnel. Every post starts here. If the brief is weak, no model can save the draft.
The job is simple. Pick a pillar. Pick a primary keyword. Set a word target. Set a funnel stage. Ship a one-paragraph angle.
We run ours in Airtable. One row per planned post. Status moves from Planned to In Progress to Ready for review to Approved to Published.
The model writes briefs from a seed list of pillars. Then a human picks which briefs go live. That human step is two minutes per brief, not two hours.
You need three things in every brief.
First, a primary keyword tied to a real search query. Not a vibe. A query.
Second, an angle that the top three ranking pages do not already cover. If your blog repeats the SERP, you do not rank.
Third, a pillar tag. Pillars group posts into clusters. Clusters are what ranks now, not single posts.
Skip any of these and the draft will be generic. Generic loses to specific every time.
Q: How many topics should the engine queue at once?
A: Queue four weeks ahead. Less and the content engine starves. More and the briefs go stale before they ship.
Engine Two: The Content Engine
This is the engine most teams already have. It is also the one most teams misuse.
The trap is treating the LLM as a writer. The LLM is not a writer. It is a draft generator. The writer is the system around it.
Here is the actual loop we run.

The model never ships a draft straight to the CMS. Every draft hits a validator script first. The validator checks word count, sentence length, paragraph depth, AI-opener phrases, filler density, and Flesch score.
If the draft fails, the system rewrites the failing sections. Three attempts max. If it still fails, the draft pauses and a human takes a look.
The validator is what stops slop. Without it, the team ships fine-looking drafts that read as AI. With it, the drafts pass a human eye test on the first attempt 90% of the time.
You can build the validator in a single Python script. Maybe 400 lines. It is the highest-leverage script in the stack.
Q: Should the LLM also generate the SEO schema?
A: Yes, but inside the draft. Embed the Article and FAQ JSON-LD as YAML frontmatter. That way one file carries the whole publish unit.
Engine Three: The Image Engine
Images used to be the slow step. Hire a designer. Wait two days. Get one cover.
That math is dead. Modern image models render covers in 20 seconds for under 10 cents. The new bottleneck is the prompt.
The trick is to separate cover from inline. Cover is editorial. It needs atmosphere. Inline is data. It needs accuracy.
Cover prompts go to a photo model. Higgsfield Soul, Flux Pro, Mystic — pick one. The brief is short. The mood matters more than the words.
Inline prompts go to two places. Diagrams, frameworks, tables, and checklists go to a deterministic SVG renderer. There is no hallucination risk when the renderer copies your source data verbatim.

Stat infographics and side-by-side comparisons go to a text-rendering model. GPT Image 2, Imagen 4 Ultra, or Nano Banana Pro. They render legible labels and numbers.
The key rule is the source data block. Every non-photo prompt carries a YAML block with the exact rows, stats, and steps that must appear in the image. The renderer copies. It does not invent.
Skip the source data block and you get hallucinated numbers in your images. That is the worst kind of bug. The image looks fine. The number is wrong.
Q: How many inline images per post?
A: Four to six for long-form. Two to three for short. One concept photo max inline. The rest should be data-driven, not decorative.
Engine Four: The Publish Engine
The publish engine is the one most teams skip. They draft. They review. They paste into the CMS by hand. Then they wonder why volume tops out.
Hand publishing is the bottleneck. Always. It does not look like a bottleneck because each post takes only 10 minutes. Ten minutes times 500 posts is 83 hours.
The fix is a script. Take the markdown file. Parse the frontmatter. Hit the CMS API. Push the post. Update the Airtable status.
We use Webflow. Most teams use WordPress. Either way, the API exists. The script is two hours of work and saves 80 hours a month.
The frontmatter is what makes this work. Every field the CMS needs lives in the file. Title, slug, meta, schema, cover image, publish date. The script reads the file and writes the CMS.
This is why the markdown artifact spec matters. One file per post. Everything inside. No side channels. No special fields.
The publish engine also flips Airtable status. From Approved to Published. Now the topic engine knows what shipped. The loop closes.
One more rule. The publish engine should be idempotent. Run it twice and nothing breaks. The script checks if a post already exists. If yes, it updates. If no, it creates. That single rule saves countless duplicate posts.
The same engine handles internal links. After publish, a second pass walks the post body and resolves [internal link: slug] tokens to real URLs. The mesh forms itself over time.
Q: What if the CMS API does not support every field?
A: Map the fields the API supports. Drop the rest into the body. Most CMS gaps are around schema, and schema injection is a 20-line script in the publish step.
The Validator: Your Quality Floor
Every other team that tried to scale before us hit the same wall. The drafts looked fine. Then a real editor read 50 of them. Half were garbage.
The fix is a deterministic validator. It runs on every draft before any human sees it.
The seven hard checks are simple.
- Word count must sit inside the target range. Below floor signals weak content.
- Average sentence length must stay under 12 words. Long sentences kill Flesch.
- The longest sentence must stay under 22 words. One run-on flags the whole draft.
- Paragraph depth tops out at three source lines. Dense blocks lose mobile readers.
- The AI-opener regex must score zero hits. "In today's world" is a trust killer.
- Filler density must sit under 10 per 100 words. Filler signals AI tells.
- The Flesch score must clear 60. Below 60 reads as corporate fog.
This list is the floor, not the ceiling. Each check is a hard fail. The validator exits with an error and the draft loops.
We added a second pass. After the deterministic pass clears, the LLM runs a self-review. It checks depth, citations, and brand voice. Those are semantic checks. A script cannot judge them.
The two-pass model catches 99% of slop. The remaining 1% is what humans review at the end.
The validator also tracks failure types over time. After a few hundred drafts, patterns show up. One model fails the AI-opener check often. Another fails the sentence length check. The data tells you which prompt to tweak.
We log every failure to a CSV. Once a week, an operator scans the log. The most common failure becomes next week's prompt fix. Slow loops. Real gains.
Q: How long does the validator run per draft?
A: Under two seconds. It is pure Python with regex and a syllable counter. No API calls. No cost.
What Most Teams Get Wrong
Most teams scale the wrong axis. They scale drafts. They do not scale checks.
Tim Soulo at Ahrefs called this out hard. He said scaling AI content is the biggest lie in content marketing. He is right when teams skip the system. He is wrong when teams build it.
Here is the checklist of failure modes we see across teams trying to scale.
- You drafted 100 posts and checked only 10. The other 90 are slop.
- You used AI for the draft but pasted into the CMS by hand. Volume capped.
- You generated images from a generic prompt. They look like every other AI image.
- You skipped the topic engine. The model picked its own briefs. The cluster never forms.
- You never wrote a validator. So you cannot tell good drafts from bad at speed.
- You added human review at the wrong step. Reviewers got buried in upstream drafts.
Each of these is a fixable hole. Plug them in order and volume climbs without quality dropping.
The pattern across every team that did scale is the same. They built systems before they bought more tools. The tools came after the systems were proven.
Q: What is the single biggest unlock for scaled content teams?
A: A deterministic validator. It compounds. Every draft that passes it is better than every draft a human reviewed in a hurry.
Build versus buy: what to outsource
You can buy parts of this stack. You cannot buy the whole thing. The glue is always custom.
Topic engines are buy. Airtable, Notion, monday — all work. Pick the one your team uses already.
Draft engines are mostly buy. Claude and GPT cover 95% of the work. Custom prompts and a system message do the rest.
Image engines are buy. The model market is mature. Higgsfield, fal.io, Imagen, GPT Image. Pick two for redundancy.
Validators are build. Every brand has its own voice rules. A generic validator will not catch your tells. Two days of Python and you have one that fits.
Publish engines are build. The CMS API is unique to each tool. The mapping from frontmatter to CMS fields is custom every time.
The glue is build. Make and n8n help. Python helps more. Either way, the wiring is yours.
If you are picking one tool to start with, pick a draft engine you already trust. The rest follows the pipe.
The other rule is to start small. Build for ten posts a week, not 500. Once ten posts a week is boring, double it. Then double again.
Teams that try to jump straight to 500 always trip. The stack is right. The team is not ready. Onboard the team to ten, then 50, then 500.
How YARD Approaches AI Content at Scale
We run this stack across client brands every week. AI-first growth marketing means the workflow is the product, not just the channel mix.
Our pipeline is four engines wired together. Airtable for topics. Claude for drafts. fal.io and a programmatic renderer for images. A custom Webflow publisher for the final push.
Each engine is observable. Each step writes status back to Airtable. A failure at any step pauses the post and pings the operator.
We do not pitch a tool. We pitch a system. Tools change every quarter. The system survives.
If you run paid and content together, the math gets more interesting. Content feeds the retargeting pool. Paid sends qualified visitors back to the cluster. The two engines reinforce each other.
The shorthand is simple. Performance marketing, LLM SEO, AI creatives, AI funnels for D2C and B2B. The work is the same. Only the channel mix shifts per client.
Want to see the stack run end to end on your topics? We will show the actual files. We will show the scripts. We will share the validator output. No demo data. Just the pipeline on real briefs.
The win is not faster blogs. The win is a content engine your team can run while they do harder strategy work.
Conclusion: Build the System, Then Add Volume
AI content marketing at scale is a system, not a tool. The teams that hit 500 posts a month built four engines and the glue between them.
Start with the publish engine. It unlocks the rest. Then add a validator. The validator pays for itself in the first 50 drafts.
Layer in image and topic engines once the spine works. Resist the urge to add more tools before the system is proven.
The bar for ranking moved up this year. AI Overviews now read every page on the SERP. The pages that win are the ones with point of view, real data, and clean structure.
Volume without that bar is noise. Volume with that bar compounds. Pick the right side of that line and content stops being a cost centre.
Is your team stuck at 20 posts a month? Want to see what 500 looks like inside your own voice? Book a call with us. We will walk through your current stack. We will show where the engines are missing. No deck. Just the live pipeline.
FAQ
Q: What is AI content marketing at scale?
A: It is a content engine that uses AI for drafting, image generation, and routing. Paired with human review at brief and edit. The goal is volume with kept quality.
Q: Can a small team really ship 500 posts a month?
A: Yes, but only with a stack. You need a topic, content, image, and publish engine. Each runs without a human in the loop most of the time.
Q: Does Google penalise AI content at scale?
A: Google penalises low-value content, not AI content. Real query, real depth ranks. If a post is filler, it gets buried. Same as bad human writing.
Q: What stack do most scaled content teams use?
A: A topic source like Airtable. An LLM for drafts. An image model. A validator script. A CMS publisher. Most teams glue it with Make or n8n.
Q: Where does the human review fit in?
A: Two places. First at the brief — pillar, keyword, and angle. Then at the final read — voice, claims, and links. Skip either and quality drops fast.
Q: How do you stop AI content from sounding generic?
A: Feed the model your point of view, real data, and live citations. Use a strict tone spec. Run a deterministic validator that flags AI tells first.
Insights from Our Experts
Explore our latest articles on digital marketing strategies.


