
Three labels keep showing up in every marketing stack. Claude. GPT. Gemini.
The honest answer to "which one" is short. None of them wins everything.
The best AI for marketing in 2026 is the one that fits the job in front of you. Claude leads on long-form writing. GPT leads on speed and tools. Gemini leads on research over huge inputs.
This guide breaks the choice down by task. We use the current versions, real pricing, and live sources. By the end you will know which model to open for which job.
A quick note before we start. We compare flagships, since that is where most teams decide.
We also keep it practical. No hype. Just what each model does best for marketing work.
Which Models Are We Actually Comparing in 2026?
Versions move fast. So let us name the exact ones.
Anthropic shipped Claude Opus 4.8 on May 28, 2026. It is their most capable model, with sharper judgement and longer independent work (Source: Anthropic, 2026 — anthropic.com/news).
OpenAI shipped GPT-5.5 on April 23, 2026. It carries a 1M token context window and serves as the new default in ChatGPT (Source: OpenAI, 2026 — developers.openai.com).
Google shipped Gemini 3.1 Pro on February 19, 2026. It supports a 1M token context window and ranks first on most of Google's tracked benchmarks (Source: Google DeepMind, 2026 — deepmind.google).
It also reads mixed media in one go. Text, images, audio, video, and PDFs.
That helps with messy marketing inputs. A brand kit and a call recording can go in together.
So all three now read very large inputs. The gap is no longer raw size. The gap is taste, speed, and cost.
One more thing to know. Each lab ships new versions fast now.
Anthropic shipped Opus 4.8 just weeks after 4.7. The pace is real.
So any "best model" call has a shelf life. Plan to re-check often.
Q: Which exact models should I compare in 2026?
A: Compare Claude Opus 4.8, GPT-5.5, and Gemini 3.1 Pro. These are the current flagships from Anthropic, OpenAI, and Google. Older version numbers like GPT-5.1 are already retired, so do not benchmark against them.
Claude vs GPT vs Gemini: The Marketing Scorecard
Here is the short version before we dig in.
Each model has a clear home turf. The trick is matching the turf to your task.
The visual below maps five common marketing jobs to a best-fit model. Read it as a quick decision aid.
Why split it this way? Because one model rarely wins every row.
A team that picks by job gets better work and a smaller bill. That is the whole idea.
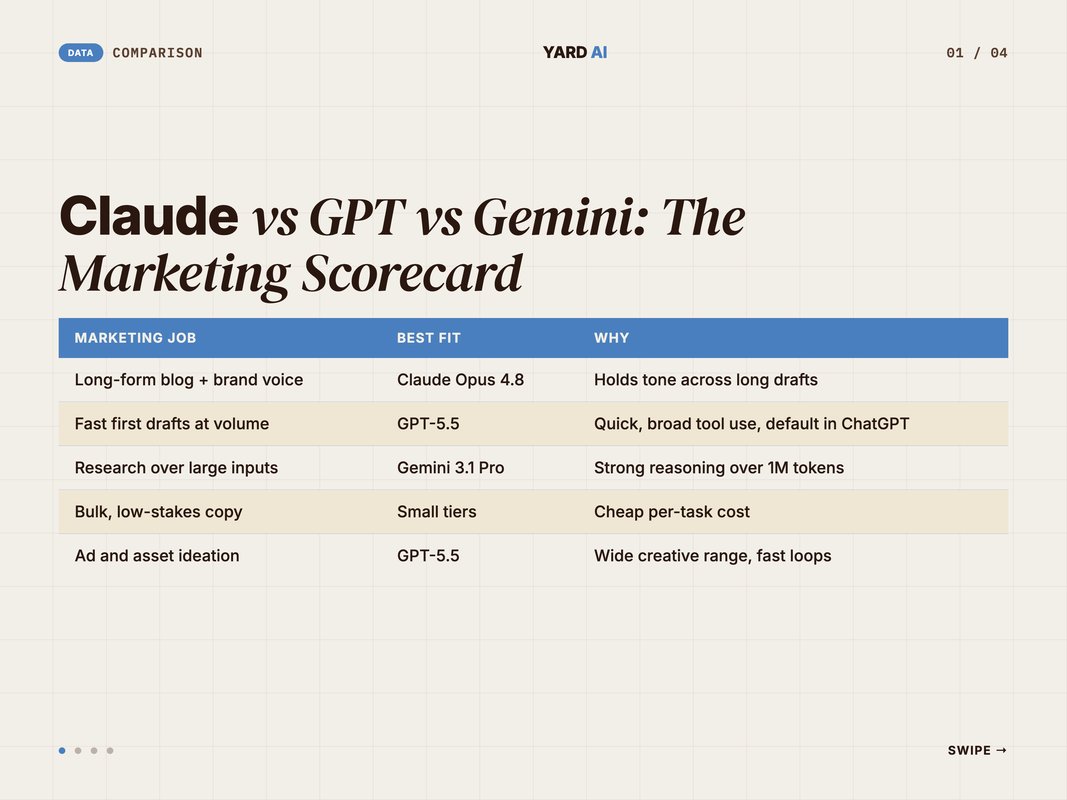
Long-form blogs and brand voice lean to Claude Opus 4.8. It holds tone across a long draft.
Fast first drafts at volume lean to GPT-5.5. It is quick and the default in ChatGPT.
Research over large inputs leans to Gemini 3.1 Pro. It reasons well over a million tokens.
Bulk, low-stakes copy leans to small tiers. They cost the least per task.
Ad and asset ideation leans to GPT-5.5 again. It loops fast and ranges wide.
Treat this as a starting map, not a verdict. Your brand voice and stack will shift a few rows.
Q: Is there one best model for all marketing work?
A: No. The scorecard shows different winners per job. A team that uses only one model leaves quality and money on the table. Match the model to the task instead.
Which AI Writes the Best Marketing Copy?
This is where most teams start. And it matters most.
Claude Opus 4.8 tends to hold brand voice across long pieces. It drifts less over a 2,000-word draft.
That matters for blogs and email sequences. The tenth paragraph still sounds like the first.
GPT-5.5 writes fast and follows layered briefs well. It is a strong pick for high-volume first drafts.
Feed it a tight brief and it nails structure. Headlines, hooks, and variants come quick.
Gemini 3.1 Pro writes clean copy too. Its edge shows more in research-heavy pieces than in pure voice.
Here is a simple way to test voice. Paste three of your best past posts as a style sample.
Then ask each model to match that exact voice on a new topic. The gap shows up fast.
You will see one model copy your rhythm and word choice. The others drift toward generic.
Try one more check. Ask each to write a single subject line for the same email.
Short tasks expose voice fast. A weak line reads flat. A strong one sounds like you.
The demand is real. About 94% of marketers plan to use AI in content creation in 2026, including blog articles (Source: HubSpot, 2026 — blog.hubspot.com).
Daily use is already normal too. About 78% of marketers worldwide use AI tools in their daily workflow (Source: HubSpot, 2026 — hubspot.com/state-of-marketing).
But raw output is not the finish line. Half of US consumers prefer brands that avoid GenAI in consumer-facing content (Source: Gartner via Customer Experience Dive, 2026 — customerexperiencedive.com).
So the model writes the draft. You keep the voice and the point of view.
The fix is a human edit. Add a real opinion. Cut the hedging. Keep your house style.
Q: Is Claude or GPT better for marketing copy?
A: Claude usually holds brand voice better across long drafts. GPT-5.5 is faster and great for volume. Run one brief through both. Keep the model that needs fewer edits from your team.
Which AI Is Best for Research and Strategy?
Copy is one job. Thinking is another.
Strategy work means reading a lot. Old decks. Call notes. Competitor pages. Past campaigns.
You want the model to hold all of it at once. Then spot the pattern you missed.
That is a different skill from writing a clean line. It is about reasoning over scale.
This is Gemini's strong lane. Gemini 3.1 Pro delivers a large reasoning boost over Gemini 3 Pro and reads across a 1M token window (Source: Google DeepMind, 2026 — deepmind.google).
Claude Opus 4.8 also reasons well and works longer on its own (Source: Anthropic, 2026 — anthropic.com/news). It is a strong pick for structured strategy memos.
GPT-5.5 holds the same large context and pairs it with fast tool use (Source: OpenAI, 2026 — developers.openai.com). That helps when research needs live web steps.
Picture a real task. You want a competitor teardown before a pitch.
You drop in ten rival landing pages and three old decks. You ask for gaps and angles.
You can add more in the same go. Past ad copy. Review screenshots. A pricing page.
The model reads it all and ranks the openings. You leave with a clear angle.
A million-token window reads all of it at once. No chopping. No lost context.
The model that reasons best over that pile wins the job. Often that is Gemini here.

A simple rule helps here.
- Pick the input size first.
- For huge mixed inputs, start with Gemini.
- For long agent runs, start with Claude.
Note the difference between size and stamina. Size is how much it reads at once.
Stamina is how long it works on its own. Claude leads on stamina for multi-step runs.
Q: Which AI is best for marketing research in 2026?
A: Gemini 3.1 Pro leads when you feed it large, mixed inputs at once. Claude Opus 4.8 leads for long, independent strategy runs. Both read up to a million tokens, so the choice is reasoning style, not size.
What Does Each Model Cost a Marketing Team?
Quality matters. So does the bill at month end.
Pricing is per million tokens. A token is roughly three-quarters of a word.
The visual below stacks the three flagships side by side. The numbers come straight from each provider.

Claude Opus 4.8 runs at $5 input and $25 output per million tokens (Source: Anthropic, 2026 — platform.claude.com).
GPT-5.5 runs at $5 input and $30 output per million tokens (Source: OpenAI, 2026 — developers.openai.com).
Gemini 3.1 Pro runs at $2 input and $12 output per million tokens, the cheapest of the three flagships (Source: Google, 2026 — blog.google).
Small tiers cut cost further. Claude Haiku 4.5 lists at just $1 per million input tokens (Source: Anthropic, 2026 — platform.claude.com).
Output is where bills grow. Long blogs and big reports spend output tokens fast.
So watch the output rate, not just the input rate. That column drives most of the cost.
Caching and batch jobs help too. Cached input and batch runs cut the rate sharply on all three.
So route smart. Send easy work to small models. Save the flagship for hard work.
A quick rule of thumb. Use a flagship for hero content and strategy.
Use a small tier for tags, alt text, and short product lines. The output reads fine.
The savings add up fast at volume. A thousand product blurbs do not need a flagship.
Run the math on your real mix. Most teams find half their tasks fit a cheap tier.
Q: Which AI model is cheapest for marketing teams?
A: Gemini 3.1 Pro is the cheapest flagship at $2 input and $12 output per million tokens. Small tiers like Claude Haiku 4.5 cost even less. Route bulk tasks to cheap models to keep the bill down.
How Do You Choose Fast Without Endless Testing?
You do not need a month of trials. You need one good hour.
Use a small, repeatable test on a real brief. Score what your team actually cares about.
Quick Facts: AI in Marketing 2026 at a Glance
- About 78% of marketers worldwide use AI tools in their daily workflow — (Source: HubSpot, 2026 — hubspot.com/state-of-marketing).
- Nearly 94% of marketers plan to use AI in content creation, including blog articles — (Source: HubSpot, 2026 — blog.hubspot.com).
- Half of US consumers prefer brands that avoid GenAI in consumer-facing content — (Source: Gartner via CX Dive, 2026 — customerexperiencedive.com).
- Among flagships, Gemini 3.1 Pro is the cheapest at $2 input per million tokens — (Source: Google, 2026 — blog.google).
Run this short test before you commit. Each line is one checkbox.
- Pick one real brief your team runs often.
- Send the same prompt to Claude, GPT, and Gemini.
- Score voice match from one to five.
- Score factual accuracy from one to five.
- Count the edits each output needs.
- Keep the model with the fewest fixes.
The winner is the one your editors fight the least. That is the real signal.
Keep the test honest. Use a brief you run every week, not a toy prompt.
Use the same inputs for all three. Same brand sample. Same word count. Same rules.
Save the scores in a shared sheet. Next quarter you repeat the test and compare.
This beats vibes and hype threads. You pick on edits saved, which is real time.
Q: How do I pick an AI model without testing for weeks?
A: Run one real brief through all three in an hour. Score voice, accuracy, and edits needed. The model with the fewest fixes wins that job. Re-check each quarter, since new versions ship fast.
Where Each Model Still Falls Short
No model is magic. Each one has a soft spot worth knowing.
Claude can be cautious. It hedges when you want a bold, sharp take.
The fix is a firm prompt. Ask for a clear stance and a strong verb.
GPT-5.5 is fast, but speed has a cost. It can sound generic on a thin brief.
The fix is more input. Give it your voice sample and three hard rules.
Gemini is strong on research, yet its plain copy can feel flat. It reads more like a report.
The fix is a second pass. Send the Gemini draft to Claude for a voice polish.
There is a shared risk too. All three can state a wrong fact with full confidence.
So every number needs a human check. Click the source. Confirm it. Then ship.
This is not a knock on AI. It is just how you run it well.
Treat each model like a sharp junior. Great speed, real skill, still needs review.
So build the check into your flow. Draft with AI. Verify every claim. Edit for voice.
That habit turns a risk into an edge. Your content stays fast and stays true.
Q: Do AI models make mistakes in marketing content?
A: Yes. All three can state a wrong fact with confidence and can drift off-voice. Always check numbers against the source and edit for tone. AI drafts the work, but a human still signs off on every public piece.
Should You Pick One Model or Use All Three?
Here is where strong teams pull ahead. They stop picking one.
The "best" model is a moving target. Versions change every few weeks now.
So the winning move is a router, not a religion. You send each task to the model that wins it.
Loyalty to one brand is a trap here. The leader changes every few weeks.
A router keeps you free. When a new model wins a job, you just swap one line.
We call this a model-routing layer. It is one rule set that maps task types to models.
Think of it as four R's. Reach, Route, Refine, Review.

- Reach: list the marketing jobs you run weekly.
- Route: map each job to its best-fit model.
- Refine: cut cost by sending easy work to small tiers.
- Review: re-test the map every quarter.
This keeps you fast and cheap. And it future-proofs you against the next release.
The router can be a real tool or a simple doc. Start with a doc.
Write one line per job. Name the model, the tier, and the reason.
Your team reads it and knows where to send each task. No guessing. No debate.
Later you can wire it into your stack. The logic stays the same either way.
Q: Can I use all three AI models together?
A: Yes, and most strong teams do. You route each task to the model that wins it. Drafting, research, and bulk work each get the right tier. A simple router rule makes this automatic.
Where YARD Fits In
Most teams know the models. Few have a system around them.
That gap is where we work. YARD is an AI-first growth marketing agency.
We run performance marketing, LLM SEO, AI creatives, and AI funnels for D2C and B2B brands. The models are tools. The routing and the editing are the craft.
We build model-routing layers so your team uses the right AI per task. Drafting, research, ads, and bulk copy each go to their best-fit tier.
We test the models so you do not have to. Every quarter, on real briefs.
Then we hand you a map. One line per job, with the model and the reason.
We also keep a human edit on every public piece. That matters more now. With half of consumers wary of GenAI content, a clear human voice is an edge, not a nice-to-have.
The result is simple to feel. Faster output, lower model spend, and copy that still sounds like you.
We also handle the boring parts. Source checks. Voice rules. Quarterly model re-tests.
That is the difference between using AI and running it well. The system is the moat.
If you want a stack that picks the best AI for marketing in 2026 for you, we can help map it. Start with one workflow and grow from there.
The Bottom Line
There is no single best AI for marketing in 2026. There is a best model per job.
Claude Opus 4.8 wins long-form writing and brand voice. GPT-5.5 wins speed and broad tool use. Gemini 3.1 Pro wins research over huge inputs and costs the least.
So stop hunting for one winner. Build a simple router instead. Map each task to its best-fit model, then send bulk work to cheap tiers.
Run the one-hour test this week. Pick winners per job. Re-check next quarter when the next versions land.
One last reminder. Keep a human in the loop on public work.
The models are strong. They are not your editor. You still own the voice and the facts.
Do that, and your stack stays fast, cheap, and on-brand. That is how you win with AI in 2026.
FAQ
Q: What is the best AI for marketing in 2026? A: There is no single winner. Claude Opus 4.8 leads on long-form writing and brand voice. GPT-5.5 leads on speed and broad tool use. Gemini 3.1 Pro leads on research across huge inputs. Pick by the job, not by the brand.
Q: Is Claude or GPT better for marketing copy? A: Claude tends to hold brand voice better across long drafts. GPT-5.5 is faster and follows complex briefs well. For blog posts and emails, test both on one prompt. Keep the model that needs fewer edits.
Q: Which AI model is cheapest for marketing teams? A: Cost depends on the model tier. Claude Haiku 4.5 runs at 1 dollar per million input tokens. Smaller GPT and Gemini tiers cost less than their flagships too. Route easy tasks to small models and save the flagship for hard work.
Q: Can I use all three AI models together? A: Yes, and most strong teams do. You route each task to the model that wins it. Drafting goes one place, research another, and bulk work to a cheap tier. A simple router rule makes this automatic.
Q: Does AI-written marketing content hurt brand trust? A: It can if you ship raw output. Half of US consumers prefer brands that avoid GenAI in consumer-facing content, per Gartner. Use AI for drafts and research. Keep a human edit and a clear point of view on every piece.
Q: How do I pick an AI model without testing for weeks? A: Run one real brief through all three in an hour. Score each on voice, accuracy, and edits needed. The model with the fewest fixes wins that job. Re-check every quarter, since new versions ship fast.
Insights from Our Experts
Explore our latest articles on digital marketing strategies.


